
Il y a maintenant fort longtemps, j’abordais rapidement les background workers et leur utilisation pour optimiser et contenir la charge d’une application web. Voici donc aujourd’hui un petit focus sur ces problématiques de gestion de charge. Je prends ici pour exemple le modèle des producteurs/consommateurs.
Contenus de la page
Problématique de consommation de ressources
Comme vous le savez sans doute, selon les opérations informatiques effectuées, les ressources nécessaires à la réalisation de ces opérations (temps calcul processeur, utilisation de mémoire vive, etc.) sont différentes.
Par exemple, la génération d’une page par php7 et son affichage par le serveur HTTP nginx sont négligeables en terme de ressources. En revanche, la génération d’un fichier PDF, par exemple, demande beaucoup plus de ressources.
Dès lors, comment faire pour « contrôler » cette utilisation des ressources serveur ? Le but étant de ne pas paralyser le serveur si 50 ou 100 utilisateurs demandent la génération d’un fichier PDF en même temps ?
Vous avez dit scalabilité ?

Scalabilité est un calque de traduction pour le mot anglais scalability. La scalabilité désigne la capacité de votre application à s’adapter à la montée en charge. C’est notamment sa capacité à conserver ses fonctionnalités et ses performances en cas de forte demande.
Il existe plusieurs façon de faire de la scalabilité et donc de tenir la charge :
- scalabilité verticale : on modifie les caractéristiques physiques (ou virtuelles) de la machine (ajout de mémoire vive, processeurs plus puissants où ajout de processeurs, etc.)
- scalabilité horizontale : on modifie le nombre de machines. Plus le nombre de machines est important, plus il sera à même de répondre à une forte demande. Dans ce cas, les connexions entrantes sont traitées par un serveur « répartiteur de charge » ou load balancer en anglais. Ce serveur va ensuite ré-acheminer la requête à l’un des serveur web selon un algorithme défini (round-robin par exemple).
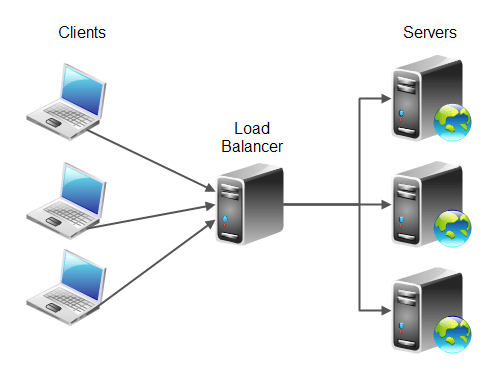
- scalabilité architecturale (ou applicative) : il s’agit ici de penser l’application de façon à ce que la consommation de ressource soit maîtrisée et optimisée. L’objectif étant que les opérations demandant beaucoup de ressources ne pénalisent pas les opérations les plus basiques.
Scalabilité architecturale/applicative : un exemple avec le modèle des producteurs/consommateurs.
Le principe ici, va être de gérer une file des opérations en attente de traitement. La file est une structure de donnée basée sur le concept du First In, First Out (FIFO) ou premier entré, premier sorti en français. On conserve donc la priorité de traitement : l’utilisateur ayant ajouté une opération à la file en premier verra cette opération traitée en premier.
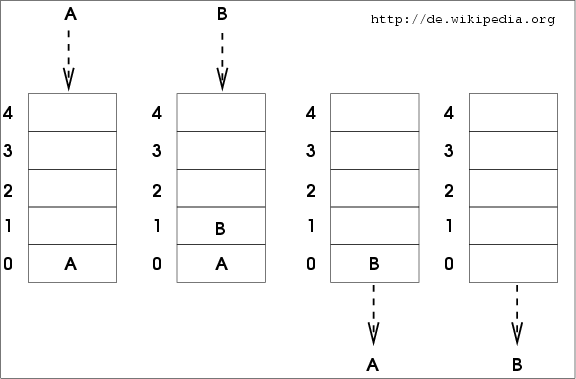
Donc, lorsque l’utilisateur demandera la génération d’un fichier PDF, l’application web (le producteur) ajoutera sa demande à la file. On peut voir la file comme une zone tampon. En parallèle, le programme/script jouant le rôle du consommateur viendra défiler (retirer de la file) la demande la plus ancienne et effectuera le traitement (dans notre cas, générer le PDF). 😌
Le gros intérêt de ce système des producteurs/consommateurs, c’est qu’il permet de choisir exactement combien de consommateurs traiteront la file. Sans ce système, si 100 utilisateurs sont connectés et demandent simultanément la génération de leur PDF, la charge serveur sera d’autant plus multipliée. Avec les producteurs/consommateurs, la tâche est ajoutée à la file et sera traitée par l’un des consommateurs. La charge serveur est donc définie par le nombre de consommateurs qui traitent les tâches déposées dans la file par les producteurs. Cela nous permet donc de contenir facilement la charge !
Ce modèle permet également une excellente répartition horizontale. Si je lance 5 processus consommateurs, la file sera traitée d’autant plus vite.
Mise en oeuvre du modèle producteurs/consommateurs dans Opencomp
beanstalkd et Pheanstalk
beanstalkd est un protocole client/serveur permettant de gérer des files d’attentes de travaux/tâches. Le serveur a été écrit en langage C (rapide) par Keith Rarick.
beanstalkd intègre des fonctionnalités intéressantes telles que la gestion des priorités. Lorsque l’on ajoute une tâche à la file, il est possible de lui assigner une priorité. Cela permet donc d’ajouter de la flexibilité à ce concept assez figé, linéaire et rigide de file. On peut, par exemple, imaginer que dans une même file, les utilisateurs payant le service bénéficient d’une priorité plus élevée dans le traitement des tâches que leurs homologues gratuits.
Le protocole est décrit de façon très détaillée dans ce document. Il nous apprend tout ce que l’on doit savoir pour interagir avec le serveur beanstalkd. 😀
Pour la partie client (permettant d’aller empiler et dépiler vers et depuis le serveur beanstalkd), j’ai choisi Pheanstalkd, une librairie cliente PHP orientée objet pour beanstalkd et correctement testée .
La partie « producteur »
Lorsque l’utilisateur demande la génération d’un bulletin PDF, l’application web CakePHP (jouant le rôle de producteur) se connecte au serveur beanstalkd et ajoute un job à la file (queue). Le serveur beanstalkd peut-être installé sur la même machine ou sur une machine différente.
La partie « consommateur »
Un Shell CakePHP (c’est à dire un script CLI : qui s’exécute en console) se charge de jouer le rôle du consommateur. Il joue donc le rôle d’un service qui s’exécute en permanence. Le service se connecte au serveur beanstalkd et surveille la file dans l’attente d’une tâche à exécuter. Dès qu’une tâche est ajoutée, il génère le PDF associé à la demande de l’utilisateur.
On peut lancer simultanément plusieurs consommateurs pour accélérer le temps de génération des PDF. 😘
Voilà, c’est la fin de ce billet ! Encore une fois, le sujet était assez technique et j’espère que je n’aurai perdu personne en cours de route ! La prochaine fois, je parlerai de Docker pour la conception d’un environnement de développement iso-prod. À bientôt