
Le billet que je vous propose aujourd’hui fait parti de ceux dont j’ai longtemps repoussé l’écriture. Et pour cause, le sujet de la représentation intervallaire est intéressant mais très technique et pas particulièrement simple à expliquer.
Nous allons donc parler aujourd’hui de hiérarchisation d’informations et d’arbres (non, ne partez pas 😇) !
Lorsque l’on souhaite gérer un système de catégories avec un niveau de profondeur infinie, deux possibilité s’offrent à nous :
Contenus de la page
Représentation classique par auto-jointure
Dans ce cas de figure, chaque enregistrement possède une clé étrangère référençant éventuellement la catégorie parente de l’enregistrement.
Il est ensuite très simple d’obtenir la catégorie parente dont l’enregistrement en cours dépends. Une simple requête SQL imbriquée permet cela. Par exemple :
SELECT *
FROM competences
WHERE id = (SELECT parent_id
FROM competences
WHERE id = 12);Ce code est parfaitement correct et nous retournera donc le nœud parent de la compétence 12, cependant, cela va poser un vrai problème quand on va souhaiter obtenir le chemin complet de la catégorie terminale (quand on parle d’arbre, la catégorie terminale s’appelle une feuille).
En effet, s’il on souhaite obtenir le chemin vers une feuille (c’est à dire récupérer toutes les catégories parentes successivement), on va être obligé d’avoir recours à une méthode récursive et on sera donc obligé de multiplier les requêtes SQL et donc, les appels à la base de données. Pour des hiérarchies très profondes, cela aura donc un impact négatif sur les performances.
La représentation intervallaire à la rescousse
Fort heureusement, il existe une méthode permettant d’améliorer grandement la lecture des structures en arbres. Elle est appelée représentation intervallaire.
Ce patron de conception (design pattern en anglais) est très performant dès qu’il s’agit de récupérer et chercher des données dans un arbre. En revanche, les performances sont mauvaises lorsqu’il s’agit de mettre à jour l’arbre (ajouter des nœuds, des feuilles, les déplacer ou les supprimer).
Cependant, il faut relativiser cet inconvénient car bien souvent, on ne met à jour que très rarement l’arbre et la plupart du temps, on ne fait que consulter ou rechercher des informations dedans 😉
Par exemple, si je prend Opencomp, les arbres sont grandement utilisés (pour les compétences des Instructions Officielles et le Livret Personnel de Compétences). Pourtant, la modification de ces arbres n’est effectuée que par l’administrateur de l’application et très rarement (nouvelles Instructions Officielles et/ou modification du Livret Personnel de Compétences).
On a donc tout intérêt à utiliser une représentation intervallaire !
Comment ça marche ? La technique :
Afin de pouvoir rechercher très efficacement dans l’arbre, chaque nœud où feuille possède deux bornes : une borne gauche et une borne droite.
Sur le schéma ci-dessous, j’ai représenté de la même couleur chaque couple de bornes (gauche et droite) correspondant à un nœud ou à une feuille de l’arbre …
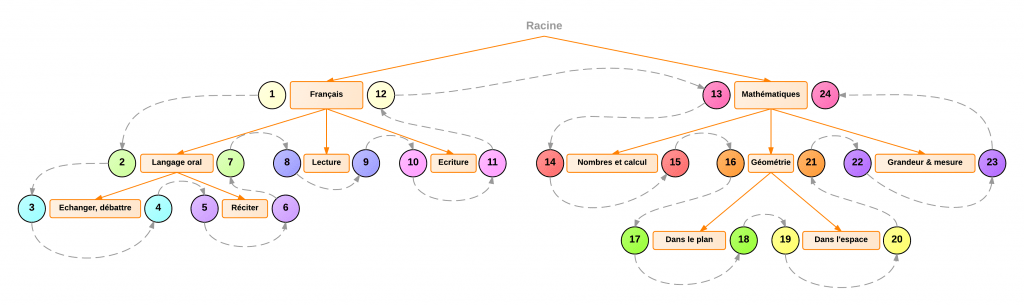
Comme vous le voyez, le principe est relativement simple. Et désormais, avec ce motif de conception, plus de requêtes à outrance pour récupérer le chemin d’un noeud : cela se fait avec une requête unique !
Cette technique de stockage des données hiérarchisées est vraiment très puissante. Pour vous en convaincre, je vous conseille de jeter un oeil à cet article qui détaille les différentes requêtes à effectuer en fonction des données que l’on souhaite récupérer.
Arbres partiels, pas de problème !
Maintenant, plus compliqué. Par rapport au schéma ci-dessus, admettons que je ne veuille récupérer qu’un arbre partiel. Par exemple, je n’ai évalué que de l’Ecriture (ayant pour borne gauche 10 et pour borne droite 11) et de la Géométrie dans l’espace (ayant borne gauche 19 et pour borne droite 20). Là encore, grâce à cette technique, c’est très simple :
SELECT * FROM competences
WHERE (lft = 10 AND rght = 11) -- Récupérer la feuille "Écriture"
OR (lft < 10 AND rght > 11) -- Récupérer les noeud parents "Écriture"
OR (lft = 19 AND rght = 20) -- Récupérer la feuille "Dans l'espace"
OR (lft < 19 AND rght > 20) -- Récupérer les noeuds parents "Dans l'espace"
ORDER BY lft; -- S'assurer que l'arbre est trié correctementEt je récupère bien uniquement mes feuilles (Écriture et Dans l’espace) ainsi que leurs nœuds parents 😉
├── Français
│ └── Écriture
└── Mathématiques
└── Géométrie
└── Dans l'espaceCalcul de profondeur des noeuds et performances
En ce qui me concerne, il reste un petit problème de performance avec la représentation intervallaire qui me chagrine : la gestion de la profondeur des différents noeuds.
Par défaut, on se retrouve avec une borne gauche et une borne droite mais rien qui persiste la profondeur. Cela signifie que pour obtenir la profondeur d’un noeud, on est obligé d’effectuer systématiquement une requête SQL. Dans le cas d’Opencomp, lorsque l’enseignant édite le bulletin d’un élève, l’application doit connaître la profondeur de chaque nœud de compétence de façon à les afficher différemment sur le bulletin généré.
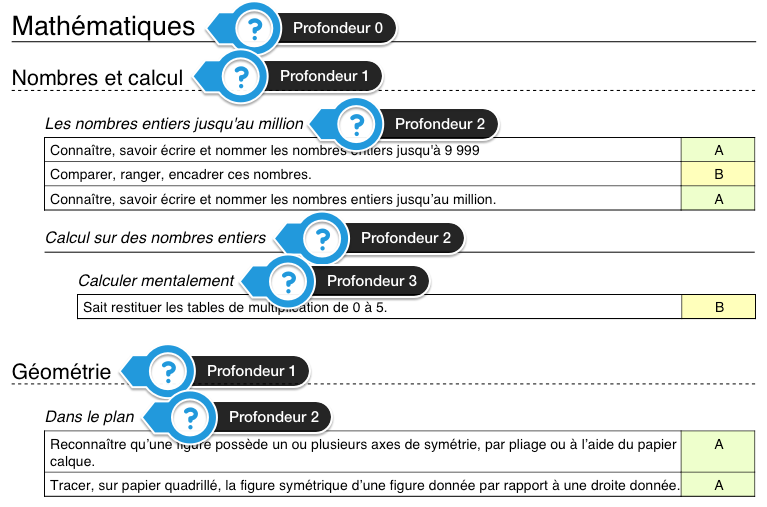
A partir de ce constat, nous avons deux solutions :
- à chaque fois qu’un bulletin doit être généré, pour chaque nœud, calculer sa profondeur (1 requête SQL par nœud).
- à chaque fois que l’arbre de compétence est modifié (nœud ajouté/supprimé/déplacé), recalculer la profondeur de l’ensemble des nœuds.
C’est bien entendu cette seconde solution que j’ai choisie. En effet, comme je vous le disait plus haut, l’arbre de compétence n’étant modifié qu’occasionnellement, il vaut mieux perdre un peu de temps à recalculer les nœuds lors d’une modification que de les calculer à chaque génération de bulletins (bien plus fréquentes).
Fonction MySQL de mise à jour de la profondeur
J’aurai pu effectuer le recalcule de la profondeur des nœud en PHP avec à chaque fois une requête permettant de récupérer la profondeur de chaque nœud puis une seconde pour persister la profondeur. Cependant, cela aurait déclenché l’envoi de beaucoup de requêtes à MySQL, ce que j’ai préféré éviter.
À la place, j’ai préféré utiliser une solution plus élégante : une fonction MySQL permettant de calculer la profondeur d’un nœud.
Je suis sur que vous avez déjà utilisé des fonctions MySQL sans même le savoir ! Si si : les fonctions d’agrégats MIN(), MAX(), COUNT(), AVG() !
Sachez qu’il est également possible de créer ses propres fonctions. Dans mon cas, la fonction se chargera simplement de calculer la profondeur d’un nœud en fonction de sa borne gauche et droite, voyez plutôt :
DELIMITER |
CREATE FUNCTION `DEPTH`(bg INT(11), bd INT(11)) RETURNS int(11)
BEGIN
DECLARE depth INT(11);
SET depth = 0;
SELECT COUNT(id) INTO depth
FROM competences WHERE (lft < bg AND rght > bd);
RETURN depth;
END|
DELIMITER ;Voilà, maintenant, c’est un jeu d’enfant pour recalculer la profondeur de chaque noeud d’un seul coup :
UPDATE competences
SET competences.depth = DEPTH(competences.lft,competences.rght);Mise à jour de la profondeur avec le framework CakePHP lors de l’enregistrement d’un nœud
C’est parfait ! Nous avons maintenant un façon simple de mettre à jour la profondeur des noeuds. Le plus simple, pour que le recalcule soit bien effectué à chaque modification d’une compétence, c’est de gérer cela par l’intermédiaire d’une fonction de rappel dans CakePHP.
Les fonctions de rappel ou callbacks en anglais sont des fonctions qui sont exécutées à certains moments du cycle de vie de l’entité (ici une compétence) manipulée. Ces fonctions permettent de respecter la bonne pratique DRY.
CakePHP dispose de plusieurs méthodes de Callback qui permettent d’effectuer des opérations sur les données à différents moments du cycle de vie de ces dernières.
Pour notre part, nous utilisons donc la méthode afterSave() pour recalculer nos profondeurs de noeuds :
/**
* Cette méthode de rappel permet de recalculer la profondeur de chaque
* item de l'arbre lorsqu'un item y est ajouté ou modifié.
*
*/
public function afterSave($created, $options = array()){
$this->query('UPDATE competences SET competences.depth =
DEPTH(competences.lft,competences.rght)');
}Cet article sur la représentation intervallaire touche à sa fin, il était assez technique. J’espère que j’aurai réussi à exposer les différentes problématiques sans que ça soit trop incompréhensible 😏
Si vous avez des questions ou des remarques, les commentaires sont là pour ça !